node-gyp如果不想安装visual studio(主要是太大了...)怎么办
以admin权限运行powershell,然后运行:
npm install -g windows-build-tools这个方式问题是他要装一个python...
以admin权限运行powershell,然后运行:
npm install -g windows-build-tools这个方式问题是他要装一个python...
参考:
JS转换HTML转义符
Decode & back to & in JavaScript
还是stackoverflow上的回答比较专业
var encodedStr = 'hello & world';
var parser = new DOMParser;
var dom = parser.parseFromString(
'<!doctype html><body>' + encodedStr,
'text/html');
var decodedString = dom.body.textContent;
console.log(decodedString);
借此写个函数
function decoder(str){
var parser = new DOMParser;
var dom = parser.parseFromString(
'<!doctype html><body>' + str,
'text/html');
var decodedString = dom.body.textContent;
return decodedString;
}TBC...
这篇文章很不错,虽然是初体验,却折腾得很有深度
Windows10内置Linux子系统初体验
教育部每年年初会在中国政府网上发布前一年的全国教育事业发展情况,可以在中国政府网上搜索“教育事业发展情况”。
2013年全国教育事业发展情况
2014年全国教育事业发展情况
中国教育概况——2015年全国教育事业发展情况
当然这个是爱迪生发明的,是通过发热到一定温度来发光,也就是黑体辐射。以前最常用的是钨丝白炽灯。
钨的熔点是3410摄氏度,大约是3680K(开尔文),所以白炽灯发热发光不能高于这个温度,其色温也往往在3000K以内。
卤素灯其实是普通钨丝白炽灯的改进。由于钨在高温下会升华,升华多了就降低了白炽灯的寿命。在白炽灯中填充卤族元素化合物(碘、溴),低温时钨与卤素化合(靠近灯泡玻璃),高温时又还原为钨(灯丝上),从而延长灯的寿命。
通过电弧在气体放电来照明的灯。很多常见灯都是这一类型。如氙气灯,实际上是高压氙气放电灯;荧光灯则是低压汞灯。
其中高压气体放电灯又被简称为HID(High Intensity Discharge)。
气压与辐射光线的关系是,低压时候,辐射基本是该气体元素的特征谱线。压力升高的时候,谱线会逐渐扩展,主要向着长波方向。压力特别高的时候,则可以接近连续光谱。
填充的气体有氙气、汞(水银)、钠、金属卤素等等。钠和汞是受高压激发后变成蒸汽才开始发生作用的。
解释一下卤族元素有哪些:卤族元素指周期系ⅦA族元素。包括氟(F)、氯(Cl)、溴(Br)、碘(I)、砹(At)、钿(Ts),简称卤素。
金属卤化物灯(金卤灯),是填充了金属与卤素的化合物,可以降低色温,提高发光效率。光效(65~140lm/w),寿命(5000~20000h),显色性(Ra65~95)。
实际是高压氙气放电灯。其发光效率在40lm/w以内。色温比较高,
实际是低压汞灯。激发汞发射253.7nm的紫外线。然后再激发荧光粉发光。
紫外线(ultraviolet,UV)按波长分为三类:长波紫外线(UVA,320~400nm)、中波紫外线(UVB,280~320nm)和短波紫外线(UVC,200~280nm)。紫外线有害皮肤。但据称只要足够远的距离(20cm以外),其影响就微不足道了。从这个角度,台灯是不适合用荧光灯做的。
荧光粉也经过了一些演化,最早是
普通的荧光粉。国家标准为QB/T2259-96 荧光灯用卤磷酸钙荧光粉
参考:(灯头的一般知识)[https://wenku.baidu.com/view/ef6602d23186bceb19e8bbad.html]
卡口(Bayonet mount):B14, B22
螺口:E10,E14,E26,E27,E40
双脚插口:G5(适用于T5),G13(适用于T8)
表示为Tn,n为数字,用于表示灯管直径。实际灯管直径(inch)=n/8,如:T5为5/8 inch, T8为1 inch。其他型号还包括T6、T10、T12。
对荧光灯来说,灯管越细,光效率越高。
栅格灯
面板灯(平板灯)
互联网据说解决了信息不对称问题,事实上并非如此。技术并不能完全解决现实问题。人类社会的现实问题受到利益驱使,只要信息有利可图,即有不对称的前提。
信息即可共生,又可互斥。GitHub是信息共生的范例,商业机密有是信息互斥的范例。有时共生和互斥也同时存在于同一类信息中,百度积极抓取其他网站内容,却又在防止其他网站抓取自己。很多网站可能对搜索引擎敞开怀抱,却又禁止其他人任一抓取。何也?利耳。
标准下载的流氓网站太多,要么没链接,要么要收钱,在百度里权重还不低……有的百度文库里面有,不过我估计百度也为了收钱,现在按文件类型搜索pdf只能找到百度文库,所以良心站只能自己找了。
国家标准全文公开系统,PC页面采用flash可以预览但无法打印,然而移动页面却可以直接Ctrl+P调出打印,页面还对打印进行了良好的支持!问题是部分采用国际标准的内容涉及版权,不给查看。
worldstdindex.com,可以搜索到中国的标准,试了一个搜到的也能下载。2018-5更新:网站悲催的挂掉了。。。
ZBGB这个站点目前下标准很爽快,没有唧唧歪歪的。2022-7更新: 网址已经打不开
我要找标准,由于防止盗链设计,下载有些费劲,但还可以下。在标准编号:后面会显示正在载入地址,过几秒后显示[ 点此下载 ]。点击显示的新页面中,还是要过几秒钟,右侧才会显示请正确输入验证码:,输入验证码并确定后会显示橙色点此下载按钮。
标准下载网,跟上面网站类似方式下载。
食品伙伴网下载中心
标准网,可搜索和下载
GB standard,可搜索,部分可免费下载
ISO YES,登录后免费下载
页面地址:http://www.51zbz.net/biaozhun/150290.html
刚进入页面:
<span id="downloadurl">正在载入地址</span>控制JS
window.setTimeout("printdownloadurl()",15000);
function printdownloadurl()
{
document.getElementById('downloadurl').innerHTML="[ <a href=# onclick=window.location.href='http://www.51zbz.net';window.open('/e/DownSys/DownSoft/?classid=250&id=150290&pathid=0')>点此下载</a> ]";
}JS执行后
<span id="downloadurl">[ <a href="#" onclick="window.location.href='http://www.51zbz.net';window.open('/e/DownSys/DownSoft/?classid=250&id=150290&pathid=0')">点此下载</a> ]</span>第二层页面地址http://www.51zbz.net/e/DownSys/DownSoft/?classid=250&id=150290&pathid=0
刚进入:
<span id="downloadurl">请仔细阅读免责声明 勿使用各类下载软件下载</span>代码
if(document.getElementById('downloadurl').innerHTML=="请仔细阅读免责声明 勿使用各类下载软件下载")
{
window.setTimeout("printdownloadurl()",18000);
function printdownloadurl()
{
document.getElementById('downloadurl').innerHTML="<table width='100%' border=0 align='center' cellPadding=0><tr><td valign='top' noWrap><form name=check method=post action=''>请正确输入验证码:<input type=text name='validatecode' value='' style='width:30px' onkeydown='if (window.event.keyCode==13) window.event.keyCode=9'><img src='code_image.php'><input type='submit' value='确定' onclick=window.open('http://www.51zbz.net/news.php?CNAS-CL08-A001:2018 .html')></form></td></tr></table>";
}
}显示后:
<span id="downloadurl"><table width="100%" border="0" align="center" cellpadding="0"><tbody><tr><td valign="top" nowrap=""><form name="check" method="post" action="">请正确输入验证码:<input type="text" name="validatecode" value="" style="width:30px" onkeydown="if (window.event.keyCode==13) window.event.keyCode=9"><img src="code_image.php"><input type="submit" value="确定" onclick="window.open('http://www.51zbz.net/news.php?CNAS-CL08-A001:2018" .html')=""></form></td></tr></tbody></table></span>确定后文件下载地址:
ftp://d73o77w37n:l73oa37dd73ow37n@down.spqs.net:8821/coyu.eu/d/file/No-Class/GB7000.202-2008_43dfbcd6a93b74011bf9fc754637bfdc.rar短距离无线协议选择,这儿有一篇小米的生态链总监孙鹏在2015年7月的文章WiFi、ZigBee、BLE用哪个?小米内部是这样选的,可作为参考。简而言之,如下:
插电的设备,用WiFi;
需要和手机交互的,用BLE;
传感器用ZigBee。
原因是什么呢?因为WIFI一旦配置好了最方便,BLE低功耗可用于电池供电的设备,传感器用Zigbee是因为那时候BLE还没有传感器的互通标准。
那么,WIFI和BLE其实是面向不同的应用,那么BLE和Zigbee重叠度就有点儿高了。在百度百科里看到Zigbee的介绍,最早作为经典蓝牙的补充,弥补其缺点的,然而后来蓝牙联盟又收了BLE,Zigbee的发展感觉有点儿难讲。
另外一篇比较BLE和Zigbee以及很少听过的ANT+的文章:BLE的最大竞争对手是ZigBee、Wi-Fi、Ant+以及一系列广泛的专有协议,转载于2016年1月,里面写到ANT+,提到一句话:
ANT+在BLE问世之前的确很成功,但在BLE问世之后,大多数此类厂商拥有了了另一个低功耗通信协议。由于BLE得到了更多主设备的支持,它被证明是一个更加保险的选择。因此,Fitbit、Jawbone、Tom-tom等主流可穿戴设备厂商都选择了BLE。
长江后浪推前浪,前浪死在沙滩上。
那么Zigbee呢,文中说Zigbee支持的终端数量更大,还支持Mesh网络,这个BLE不支持。
从这篇文章:蓝牙会干掉Zigbee吗?的观点来看,在消费者领域,蓝牙很可能会干掉Zigbee了,而在工业领域,由于其冗余性、大规模的特点,可能Zigbee仍有用武之地。
如果WiFi和蓝牙将在家庭市场一统江湖,分别垄断固定和移动连接,那么乐鑫的ESP32看来是大有前途咯!
视觉测量学是依据人眼对亮度的知觉来测光的科学。这与测量人体对射频吸收量的射频测量学(Radiometry)相区别。现代视觉测量学中,每种波长的射频能量计算
Photometry is the science of the measurement of light, in terms of its perceived brightness to the human eye.[1] It is distinct from radiometry, which is the science of measurement of radiant energy (including light) in terms of absolute power. In modern photometry, the radiant power at each wavelength is weighted by a luminosity function that models human brightness sensitivity. Typically, this weighting function is the photopic sensitivity function, although the scotopic function or other functions may also be applied in the same way.
功率因数指的是有效功率与总耗电量(视在功率)之间的关系,也就是有效功率除以总耗电量(视在功率)的比值。 基本上功率因素可以衡量电力被有效利用的程度,当功率因素值越大,代表其电力利用率越高。
参考文章:
也谈灯具的功率因素
详解LED灯具的功率因数
1cd即1000mcd是指单色光源(频率540X10^12HZ)的光,在给定方向上(该方向上的辐射强度为(1/683)瓦特/球面度))的单位立体角发出的光通量。
用I表示光学中的光强,v表示光的频率,A为照射区域面积,N为时间间隔t内照到A上的光子总数,则
I=Nhv/At
发光体在给定方向上的发光强度是该发光体在该方向的立体角元dΩ内传输的光通量dΦ除以该立体角元所得之商,即单位立体角的光通量.
I=dΦ/dΩ
1cd = 1lm/sr
1流明,物理学解释为一烛光(cd,坎德拉Candela,发光强度单位,相当于一只普通蜡烛的发光强度)在一个立体角(半径为1米的单位圆球上,1平米的球冠所对应的球锥所代表的角度,其对应中截面的圆心角约65°)上产生的总发射光通量。
E=Φ/S
Φ-光通量(Lm)
S-受照面积(㎡)
这儿有一篇针对显色指数非常好的知乎问答:目前显色指数最高的光源?
显指最好的是黑体辐射,白炽灯、卤素灯是黑体辐射原理发光的,所以显指几乎是100。
上文中有讨论显指的局限性,说显指还是需要结合色域才更能说明色彩还原度。
为弥补CRI的不足而创立的一个新标准。
CQS与CRI的对比分析
Duv(Distance to black body locus), uv指的是色品图里面的U坐标和V坐标。Duv描述照明白光与黑体辐射曲线的距离。
黑体辐射不同温度(色温)时,在色品图(色坐标)中移动的轨迹。
一个颜色(YUV)去掉了亮度值Y,剩下的就是色度。由UV组成。
你们天天纠结要小于19的UGR眩光表格到底该怎么看?
人工光源无眩光:UGR方法的背后是什么(英文)
上海科涅迩光电,光度计量仪器制造,眩光测量
LPD: Lighting Power Density,建筑的房间或场所,单位面积的照明安装功率(含镇流器,变压器的功耗),单位为:瓦/平方米。
单位为SDCM(Standard Deviation Color Matching,标准偏差颜色匹配),有欧盟IEC和美国能源之星两个标准。两者都定义了一系列标准色温,有部分色温名称一致,但是CIE色度图上的中心点却不同。欧盟为椭圆表示不同色容差,美国为菱形表示不同色容差。
欧盟ERP指令(1194/2012)要求LED <6SDCM,中国国标GB24823-2009要求<7SDCM。
维基百科:麦克亚当椭圆
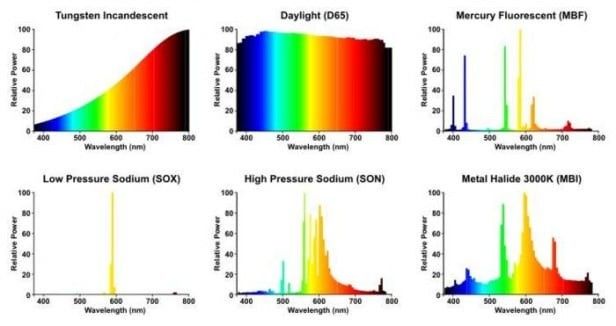
常见光源的光谱可以英文搜索lamp light spectrum,这儿引用一下:
incandescent 白炽
fluorescent 荧光
halogen 卤素
sodium 钠
tungsten 钨
halide 卤化物


固态这个词其实就是指半导体。问什么叫固态似乎也是个历史问题了,参考知乎的:固态硬盘,固态照明(LED)为什么被称为「固态」?
百度文库-照明术语
百度文库-照明术语一览表
舒适高效的办公照明VDT环境下照明设计探讨
Sekonic定义的一些术语
CCT = Correlated Color Temperature
Δuv = Color Shift (off of Kelvin Line)
CCi = CC Index Correction
CCCF = CC Camera Filter Correction
CCLF = CC Lighting Filter Correction
LBi = LB Index Correction (Mired)
LBCF = LB Camera Filter Correction
LBLF = LB Lighting Filter Correction
Lux = Illuminance (brightness)
fc = Foot Candles (brightness) 有两个标准:
ANSI White
[EVP White]()
利用系数值应按墙壁和顶棚的反射系数及房间的受照空间特征来确定。房间的受照空间特征 用一个“室空间比”(room cabin rate,缩写为RCR)的参数来表征。 如图8-12所示,一个房间按受照的情况下不同,可分为三个空间:最上面为顶棚空间,工作面以下为地板空间,中间部分则称为室空间。对于装设吸顶灯或嵌入式灯具的房间,没有顶棚空间;而工作面为地面的房间,则无地板空间。 室空间比 RCR=5hRC(l+b)/lb: 公式中 hRC,代表室空间高度; l,代表房间的长度; b,代表房间的宽度。 根据墙壁、顶棚的反射系数(参看表8-1)及室空间比RCR,就可以从相应的灯具利用系数表中查出其利用系数。
Chrome浏览器下载提示恶意文件,或者来自于不受谷歌信任的网站,即使你将此文件下载完,也会提示“chrome已经将其拦截”,给你的按钮只有“放弃”。点击放弃以后,可是哪儿都找不到……其实我下载的就是一个.zip,里面是人畜无害的.pdf文件,怎么找回呢?
再次重新下载,可以使用“另存为”存到桌面,这时候桌面将生成一个临时文件,名字是xxxxx.crdownload,等待下载完毕,弹出让你“放弃”的按钮,千万别放弃,把这个.crdownload文件复制一份,或者改个名,加上它本来的后缀,如.zip,你就成功保全了它。
LED照明标准查询
北美照明协会IES,或称为IESNA,Illuminating Engineering Society of North America,其标准以IES打头
国际电工委员会IEC,International Electrotechnical Commission,其标准以IEC打头
国际照明委员会CIE,International Commission on Illumination,CIE为其法文缩写 Commission internationale de l'éclairage
电气和电子工程师协会IEEE,Institute of Electrical and Electronics Engineers,其标准委员会为IEEE-SA(standard association)。IEEE额Xplore计划,将部分标准0费用面向公众下载,官网为[IEEE Xplore]。(http://ieeexplore.ieee.org/Xplore/guesthome.jsp)。这儿有一份[IEEE Xplore的介绍](https://wenku.baidu.com/view/ed2596dbbed5b9f3f80f1c1f.html)。IEEE的标准制定遵循[开放性标准原则](https://open-stand.org/).
国际照明设计师协会IALD,全球照明界的“奥斯卡”
中国国家标准化管理委员会SAC
国家技术标准资源服务平台:标准在线搜索和阅读
国家电光源质量监督检验中心
中国标准在线服务网:标准购买
中国标准化研究院
中国照明学会CIES
中国照明电器协会
国家半导体照明工程研发及产业联盟CSA,CHINA SOLID STATE LIGHTING ALLIANCE,秘书处为民办非营利机构—北京半导体照明科技促进中心。
半导体照明产业技术创新战略联盟,找不到专门的官网,只有在中国产业技术创新战略联盟下有一个页面。行业地位不明。此网站copyright信息在2011年,似乎自那以后都没有更新过了。
全国照明电器标准化技术委员会,介绍站点,是国标制定单位,为1975年成立的全国电光源标准化中心旗下单位,1997年为与国际接轨而成立,是国际电工委员会IEC(TC34)的国内技术归口单位。秘书处设在北京电光源研究所。
中国照明电器协会标准化技术委员会,是中国照明电器协会旗下的标准化机构。
中国LED智慧照明应用与推广研讨会
中山市半导体照明行业协会, 英文名Zhongshan Semiconductor Lighting Industry Association,缩写为ZS-SLIA,只是网站打不开...
中国之光网:中国照明电器学会官网
中国照明网:中国照明学会官网
LED网
中国半导体照明网
中国灯具商贸网
《中国标准化》杂志
路灯控制管理系统系列标准等一批照明电器相关国家标准发布
两项LED产品光辐射国家标准发布
康康,腾讯儿童台灯生产和销售,可能是目前最好的学习台灯。
阳光流
厦门,立达信LEEDARSON, 教育照明网站,一灯一世界网站:校园照明、高端家庭照明、台灯、移动照明
厦门,捷能通Nonton:校园照明、台灯
宁波,凯耀照明KLITE, 集团网站:校园照明,
杭州,纳晶科技LEDISUN,新三板代码830933:量子点LCD、LED开发制造、台灯
佛山,国星光电,主板上市企业,代码002449,LED和灯具开发制造
上海,国幸中国照明,专注于教室健康照明研究和开发
安徽亳州利辛县,九州天极之光,自研无极灯用于教室照明
浙江上虞,阳光照明,主板上市企业,代码600261,在上虞、安徽、河内等地有工厂,灯具范围广泛,包括台灯、智能家居、学校、办公、商业等等。
深圳,汉鼎照明, LED路灯、隧道灯等,以及节能改造项目EMC(Energy Management Contracting)合同能源管理
扬州,科盟,LED灯具制造
深圳,聚飞,LED封装
深圳,春发光电科技有限公司,LED封装工厂
台北,森田光電有限公司,LED封装工厂
厦门,三安光电,主板上市,代码600703,LED芯片公司,收购有美国LED芯片制造和封装公司朗明纳斯公司Luminus Devices,原持有台湾璨圆光电股份19.77%,后由于晶元光电全资收购璨圆而持有台北晶元光电公司股份3.1%,2017年9月已将所持股份完全清退。
台北,晶元光电,LED芯片公司
台中力玛科技LIXMA,灯具制造企业,为台灣勁越(股)有限公司2003年成立。
欧迪电器,浙江绍兴的台灯代工厂
(瑞丰光电)[http://www.refond.com/#]上市企业,深圳LED灯珠厂商,立达信供货商
美国加州,普瑞Bridgelux,LED芯片公司
美国,科锐Cree,纳斯达克上市企业,LED芯片公司
照明设施经济运行征求意见稿
中国标准化研究院参与牵头的国家重点研发计划专项“光与健康”在苏州启动, 2017-11-23
“中小学教室照明标准”将列入2018年广州民生实事?
时钟不停歇 旧去新来
最冷的日子还没结束 却已经期待春暖花开
或许不应期待更多的阳光
现在还能享受冬日里的晴朗
只是一年年地去了又来
我奢望日子 还有很长很长
很长很长 很长很长
长长短短 短了不再长
长得已经看惯桑田沧海
长得已经看惯爱浓情殇
长得已经不敢奢望更长
活着一刹那 一刹那有多长
